|
|
# Geological data example
|
|
# Example methodology description
|
|
|
|
|
|
|
|
## Data Description
|
|
|
|
|
|
|
|
|
|
The data set contains 9 variables with 442 samples. The target variable for prediction in the following example is 'Depth'. The variable is also used to visually evaluate sampling quality via distribution plot.
|
|
Both examples consider the following combinations of hyperparameters used for Bayesian network learning:
|
|
|
|
|
|
|
|
This and the next example consider the following combinations of hyperparameters used for Bayesian network learning:
|
|
|
|
|
|
|
|
|
|
* K2 metric;
|
|
* K2 metric;
|
|
|
* K2 metric with gaussian mixtures (GMM);
|
|
* K2 metric with gaussian mixtures (GMM);
|
| ... | @@ -13,25 +9,63 @@ This and the next example consider the following combinations of hyperparameters |
... | @@ -13,25 +9,63 @@ This and the next example consider the following combinations of hyperparameters |
|
|
|
|
|
|
|
All the examples are executed using cross-validation.
|
|
All the examples are executed using cross-validation.
|
|
|
|
|
|
|
|
## K2 metric sampling example
|
|
# Geological data example
|
|
|
|
|
|
|
|
## Data Description
|
|
|
|
|
|
|
|
The data set contains 9 variables with 442 samples. The target variable for prediction in the following example is 'Depth'. The variable is also used to visually evaluate sampling quality via distribution plot.
|
|
|
|
|
|
|
|
## Sampling
|
|
|
|
|
|
|
|
### K2 metric sampling example
|
|
|
|
|
|
|
|
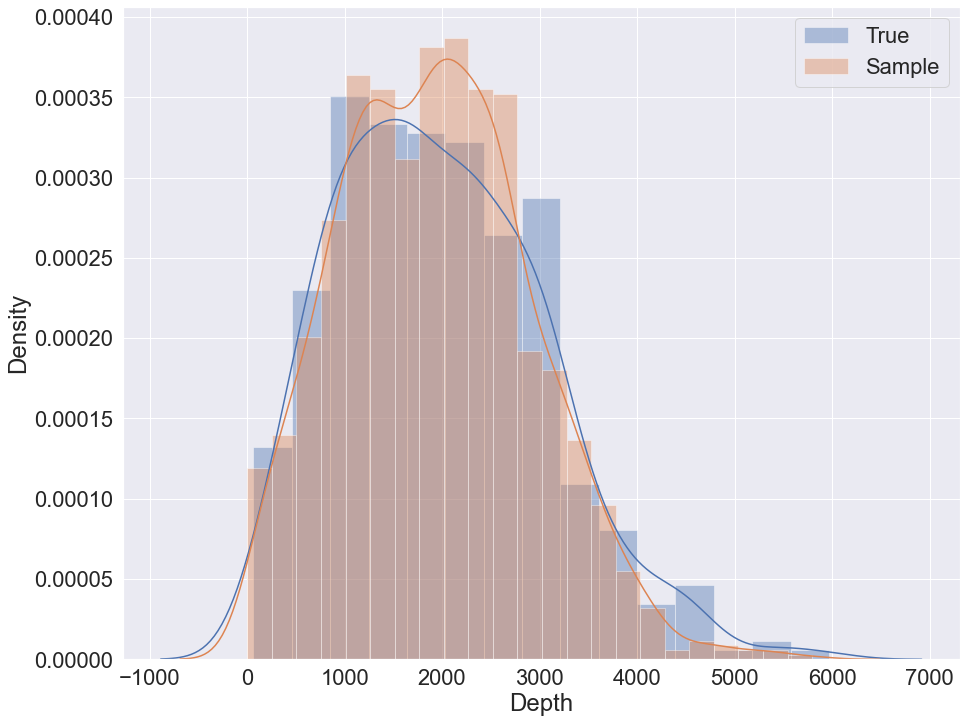
|
|

|
|
|
|
|
|
|
|
## Sampling with K2 + GMM example
|
|
### Sampling with K2 + GMM example
|
|
|
|
|
|
|
|
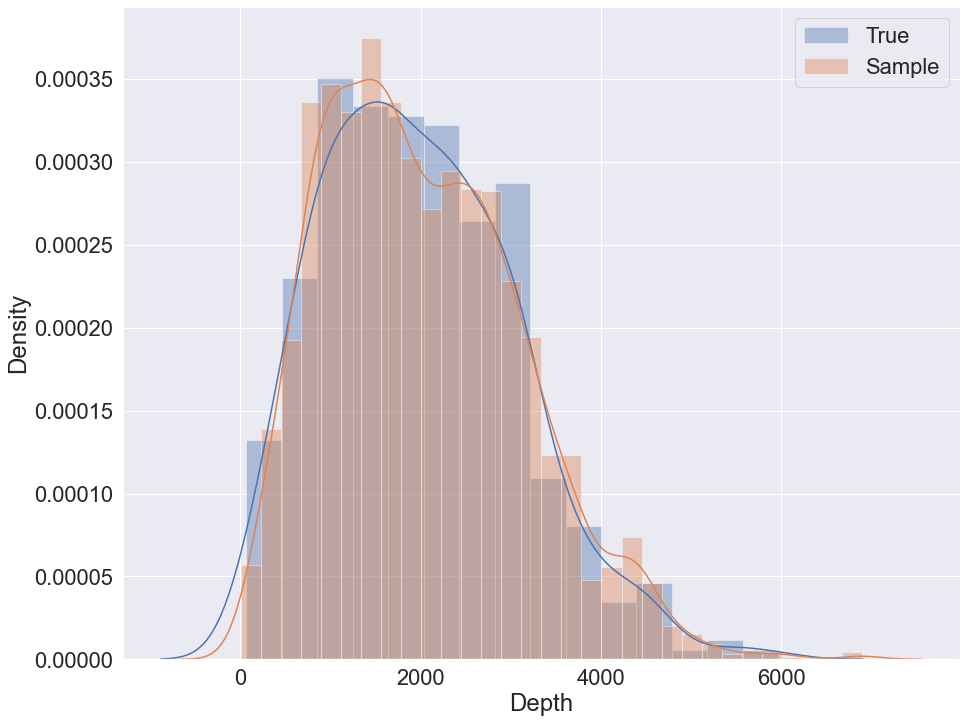
|
|

|
|
|
|
|
|
|
|
## Sampling with K2 + GMM + logit nodes example
|
|
### Sampling with K2 + GMM + logit nodes example
|
|
|
|
|
|
|
|
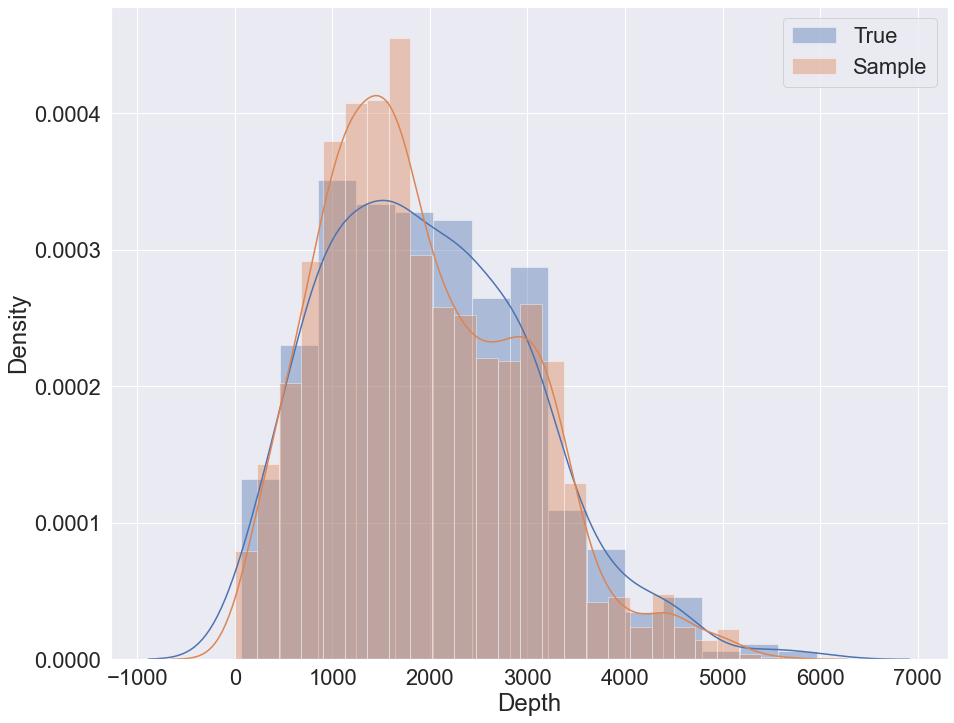
|
|

|
|
|
|
|
|
|
|
## K2 with initial structure sampling
|
|
### K2 with initial structure sampling
|
|
|
|
|
|
|
|

|
|

|
|
|
|
|
|
|
|
|
|
|
|
|
# Social data example
|
|
# Social data example
|
|
|
|
|
|
|
|
The second example is similar to the previous one, but carried out on different data set. Social data set consists of 30000 anonymous bank records with 9 variables each, bayesian networks were learnt on a sample with 2000 records.
|
|
## Data Description
|
|
|
|
|
|
|
|
The second example is similar to the previous one, but carried out on different data set. Social data set consists of 30000 anonymous bank records with 9 variables each, bayesian networks were learnt on a sample with 2000 records. The target variable is 'mean_tr' which is mean transaction of client.
|
|
|
|
|
|
|
|
## Sampling
|
|
|
|
|
|
|
|
### K2 metric sampling example
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
### Sampling with K2 + GMM example
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
### Sampling with K2 + GMM + logit nodes example
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
### K2 with initial structure sampling
|
|
|
|
|
|
|
|

|
|
|
|
|
|
|
|
|
# Prediction MSE table for both examples
|
|
|
|
|
|
|
|
|
| Hyperparameters combinations | Geological data MSE | Social data MSE |
|
|
|
|
|------------------------------|---------------------|-----------------|
|
|
|
|
| K2 | 1014.59 | 6066.5 |
|
|
|
|
| K2 + GMM | 974.35 | 5149.5 |
|
|
|
|
| K2 + GMM + logit | 1018.84 | 6657.93 |
|
|
|
|
| K2 + initial structure | 1056.06 | 12506.47 | |
|
|
|
\ No newline at end of file |
